1. Getting Started with Escher-Trace
1.1 Introduction
Escher-Trace simplifies the process of analyzing isotope tracing data by generating publication quality graphs of stable isotope tracing data on top of a metabolic map. The goal of this visualization tool is to make 13C isotope tracing data more accessible by improving data presentation and streamlining analysis.
Stable isotope tracing is a technique used to track the passage of an isotope through metabolic pathways in order to understand metabolic fluxes. By applying a stable isotope labeled metabolite to a cell or in vivo system, insight into how that metabolite is catabolized can be made by analyzing where the heavy isotopes go.
1.2 Integration with Escher
Escher is a web application for visualizing metabolic pathway maps. More information about what Escher is and how to use it can be found in the Escher Guide. Escher-Trace allows users to overlay metabolic tracing data on top of Escher maps. Because Escher-Trace is built on top of Escher, users have full access to all of Escher's features including loading, saving, and editing metabolic maps.
1.2.1 Escher-Trace Metabolic Maps
Currently there are maps of the TCA Cycle, Serine metabolism, and Branched Chain Amino Acid catabolism available. Other maps are available through the use of Escher, in order to understand how to get these maps use the Escher Guide to import the desired map.
1.3 Importing Tracer Data
1.3.1 Data Format
Baseline corrected mass spectrometer labeling data can be imported into Escher-Trace in CSV format. If the data has not been corrected for natural isotope abundance, Escher-Trace can apply the correction using the algorithm proposed by Fernandez et. al (ref). Natural isotope abundance correction is especially important for analyzing 13C tracing data as 13C is highly abundant (>1%) on earth.
1.3.1.1 Example Data Files
1.3.1.2 Natural Isotope Uncorrected CSV Format
Uncorrected tracing data can be imported into Escher-Trace in the following CSV format:
| Metabolite | Formula | Fragment | Sample 1 | Sample 2 | Sample 3 |
|---|---|---|---|---|---|
| pyr_c | C6H12O3N1Si | pyr174(M0) | 6.44E+04 | 6.22E+04 | 5.04E+04 |
| pyr175(M1) | 1.73E+04 | 1.67E+04 | 1.68E+04 | ||
| pyr176(M2) | 3.22E+04 | 2.99E+04 | 21802 | ||
| pyr177(M3) | 1.00E+06 | 9.75E+05 | 728237 | ||
| lac__D_c | C10H25O2Si2 | lac233 | 3.16E+05 | 2.76E+05 | 1.93E+05 |
| lac234 | 189244 | 155819 | 126226 | ||
| lac235 | 7073389 | 7.10E+06 | 5.09E+06 | ||
| lac__D_c | C11H25O3Si2 | lac261 | 1.06E+06 | 750924 | 7.03E+05 |
| lac262 | 253442 | 178834 | 166985 | ||
| lac263 | 1.10E+05 | 76515 | 7.08E+04 | ||
| lac264 | 1.74E+04 | 1.43E+04 | 12548 |
Important formating details for uncorrected data:
- The first row of the CSV must include the following headings in order: Metabolite, Formula, Fragment followed by the sample names
- Metabolite and Fragment entries should only use alpha-numeric characters, non-alpha-numeric characters will be replaced with underscores ("_") by Escher-Trace.
- Entries in Metabolite and Formula columns indicate that data for a new fragment is being entered, thus only include these entries in rows containing your unlabeled (M0) counts. The entry in the Fragment column of these rows is used to identify metbolite fragments and title graphs in Escher-Trace.
- If including data measured from multiple fragments for the same metabolite, simply enter the same Metabolite name for all fragments.
- The isotopologue '(M0)' does not need to be included in fragment name, the first row of data for each fragment is assumed to be M0, the second M1, and so on.
- Chemical formulas must be entered in in empirical format, absent of any non alpha-numeric characters (such as "()", "{}", etc.).
- Isotopologue counts should be baseline corrected inorder to obtain accurate corrected labeling distributions.
- Inorder to have data appear next to specific escher metabolite node, use the bigg_ID of the desired metabolite node as the metabolite name.
NOTE: Natural isotope abundance correction is made by applying the algorithm introduced by Fernandez et. al (reference).
1.3.1.3 Natural Isotope Corrected CSV Format
Tracing data that has already been corrected for natural isotope abundance be imported into Escher-Trace in the following CSV format:
| Metabolite | Fragment | Sample 1 | Sample 2 | Sample 3 |
|---|---|---|---|---|
| pyr_c | Abundance | 1.18E+05 | 1.04E+05 | 9.14E+04 |
| pyr174(M0) | 6.89E-01 | 5.29E-01 | 5.99E-01 | |
| pyr175(M1) | 2.34E-01 | 3.28E-01 | 2.88E-01 | |
| pyr176(M2) | 0.067686599 | 7.30E-02 | 8.07E-02 | |
| pyr177(M3) | 8.11E-03 | 2.71E-02 | 1.66E-02 | |
| lac__D_c | Abundance | 8.35E+06 | 6.52E+06 | 5.97E+06 |
| lac233 | 0.756372157 | 0.753097593 | 7.55E-01 | |
| lac234 | 1.62E-01 | 1.63E-01 | 1.62E-01 | |
| lac235 | 6.92E-02 | 7.04E-02 | 6.96E-02 | |
| lac__D_c | Abundance | 1.33E+07 | 1.03E+07 | 9.51E+06 |
| lac261 | 7.44E-01 | 7.43E-01 | 7.46E-01 | |
| lac262 | 0.170303805 | 1.69E-01 | 0.168789662 | |
| lac263 | 7.21E-02 | 7.24E-02 | 7.18E-02 | |
| lac264 | 1.10E-02 | 1.29E-02 | 0.010998063 |
Important formating details for corrected data:
- The first row of the CSV must include the following headings in order: Metabolite, Fragment followed by the sample names
- Metabolite and Fragment entries should only use alpha-numeric characters, non-alpha-numeric characters will be replaced with underscores ("_") by Escher-Trace.
- Entries in Metabolite column indicate that data for a new fragment is being entered, thus only include these entries in rows containing your fragment abundance. The entry in the Fragment column directly below the "Abundance" entry is used to identify metbolite fragments and title graphs in Escher-Trace
- If including data measured from multiple fragments for the same metabolite, simply enter the same Metabolite name for all fragments.
- The isotopologue '(M0)' does not need to be included in fragment name, the first row of data for each fragment is assumed to be M0, the second M1, and so on.
- Inorder to have data appear next to specific escher metabolite node, use the bigg_ID of the desired metabolite node as the metabolite name
1.3.2 Loading Data in
Now that the file is properly formatted, it is time to import the data to the Escher-Trace.
First click on the blue Import Tracing Data button in the bottom right of the screen.
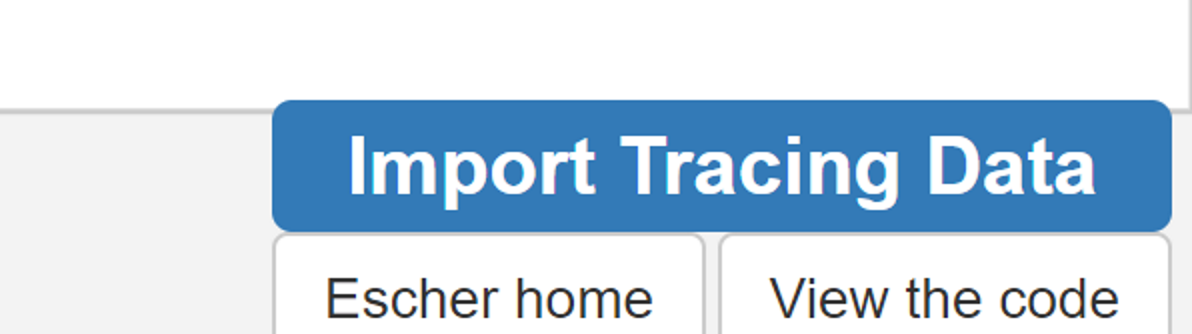
Depending on the format of the data you are uploading (baseline corrected CSV, natural isotope corrected CSV, or previously saved Escher Workspace JSON) Click Choose File and Import your data.
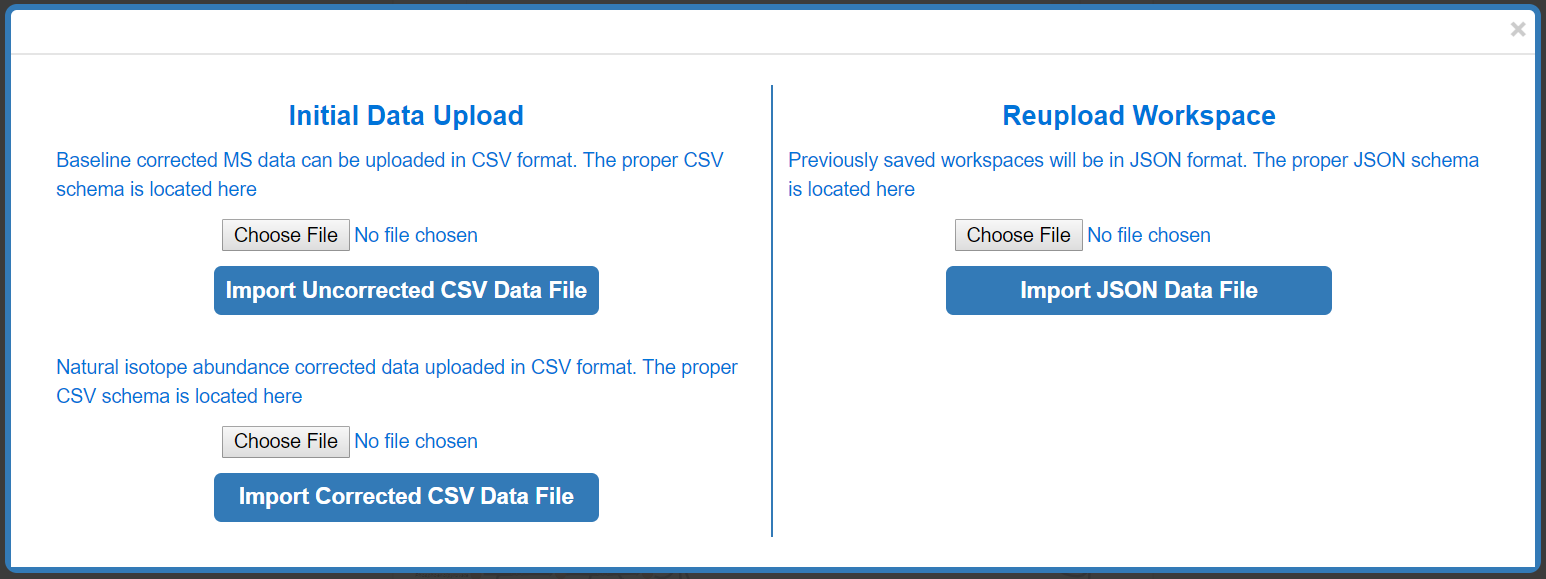
If the user is uploading data for the first time the "Sample Groups" popup will appear, if they are reuploading a previously saved Escher-Trace workspace then the previous workspace (graphs) will be displayed.
1.3.3 Organize Samples
Escher-Trace generates graphs by averaging data from samples which are grouped together. For example, if you ran an experiment with two experimental conditions, (-)Drug and (+)Drug, these would be the groups you would need to create and organize your sample data files into. To begin creating groups, click the white text input box next to Group Name: and type the desired group name. Then click Add Group
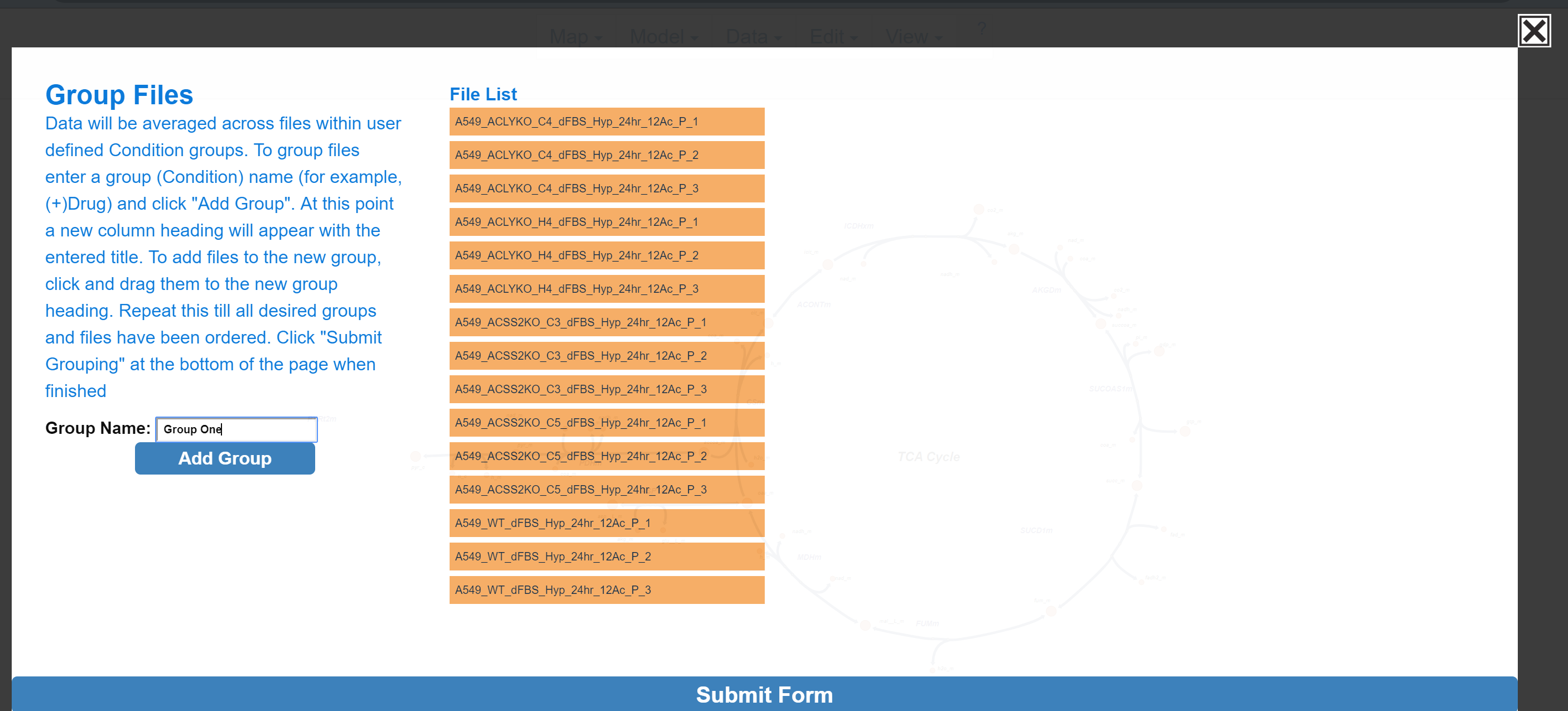
After Add Group:
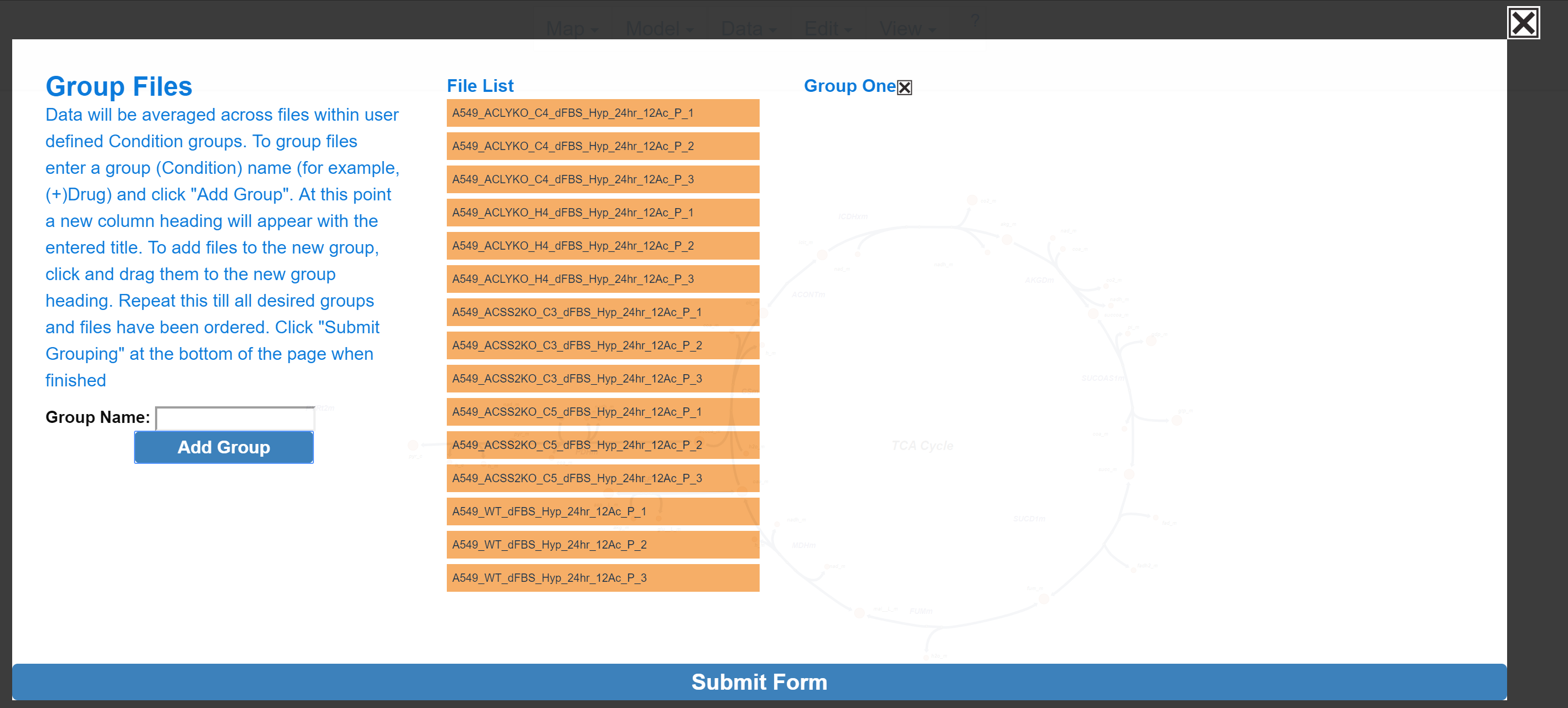
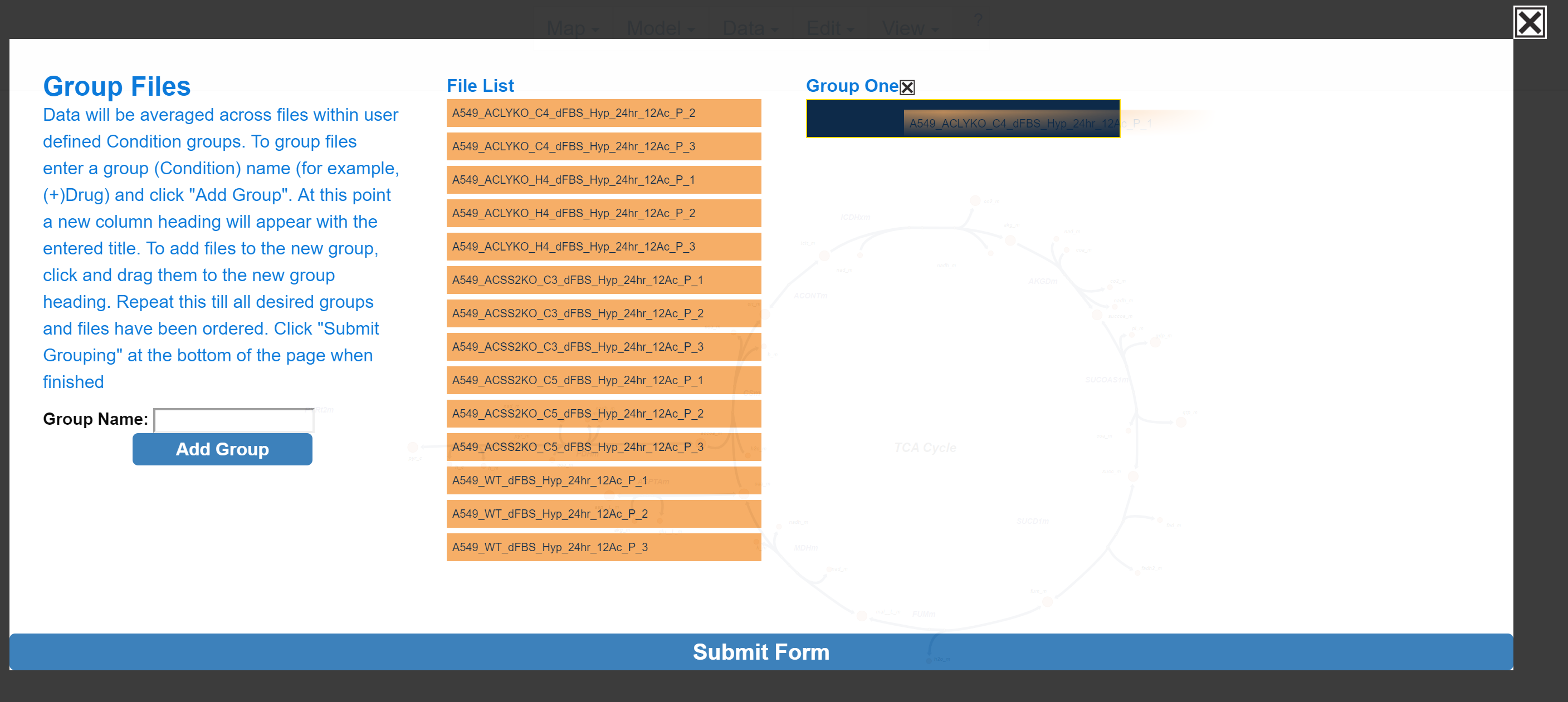
To assign a specific data file to a group, click and drag to the data file right below the desired group name, wait for the blue rectangle to appear and let go of the click.
To move multiple samples at the same time, click all sample's that you would like to move. Selected samples will turn red.
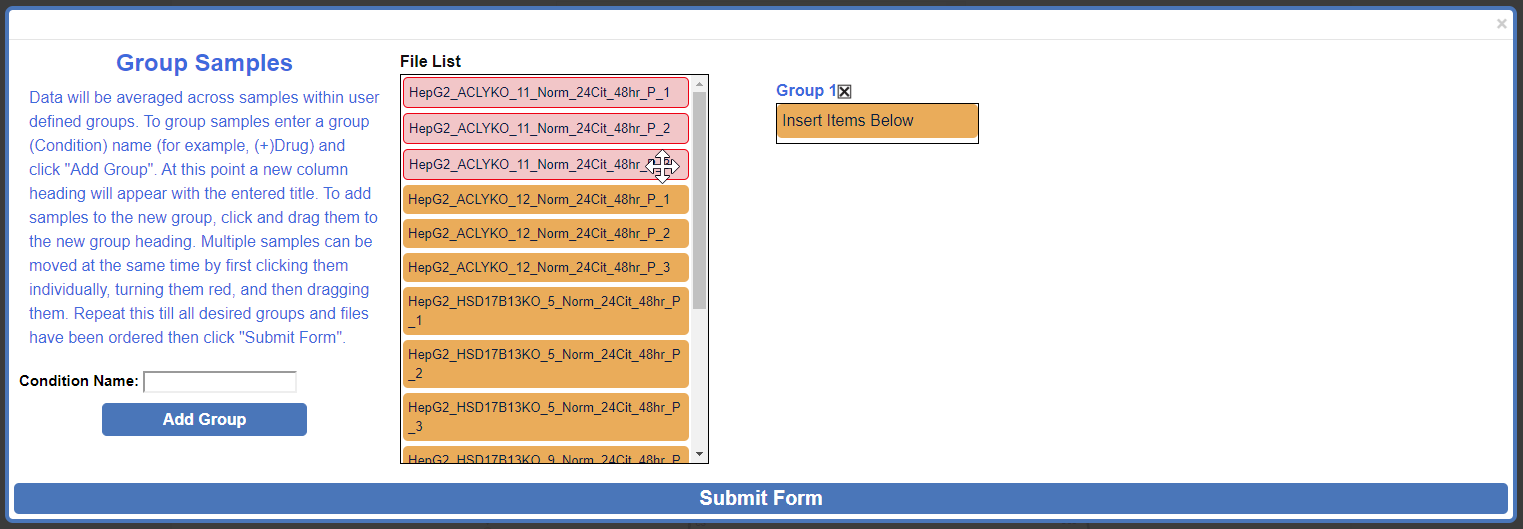
Click and drag one of the selected (red) samples to the desired group and release.
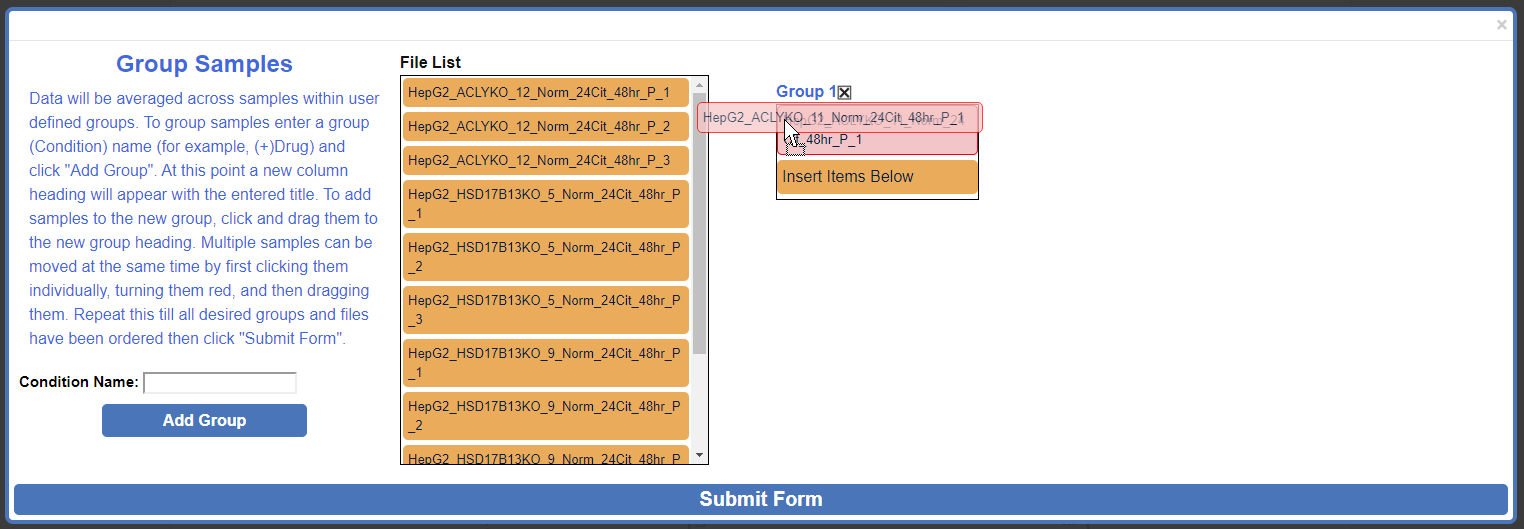
After moving multiple samples:
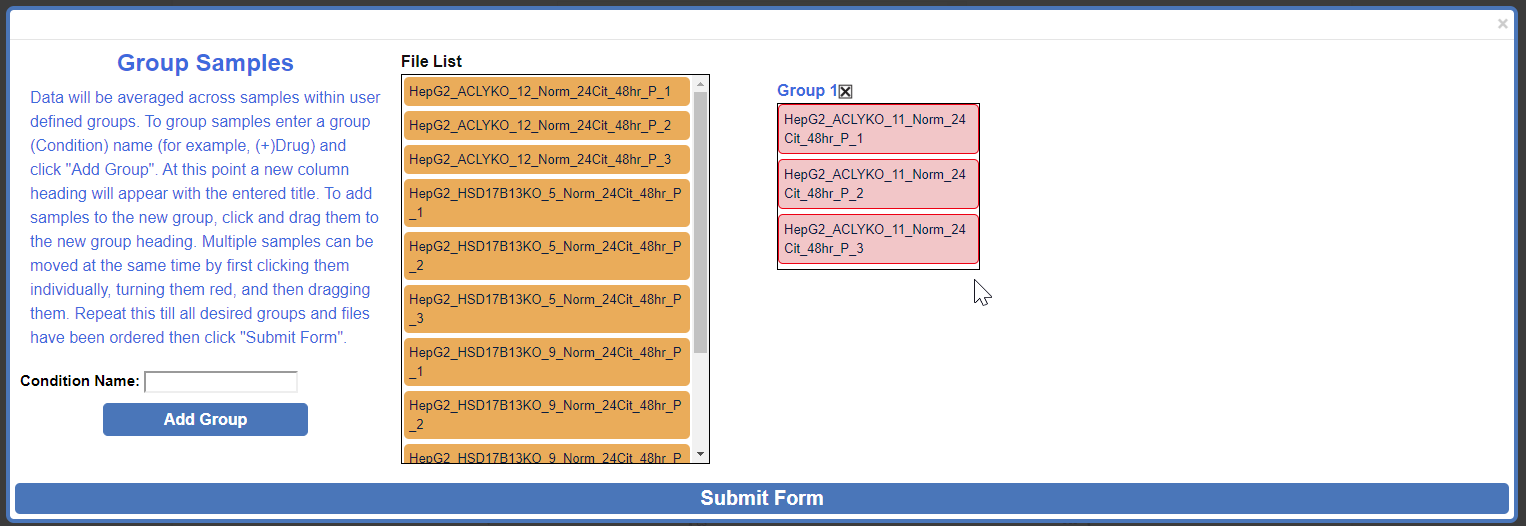
Repeat these steps as needed. When finished click Submit Form.

If the file uploaded properly, bar graphs will appear around the metabolic map and a menu will appear in the top right of the screen.
NOTE: If BIGG ID's were used for metabolite names in the submitted CSV or JSON data file, the data for those metabolites will appear next to the corresponding node on the Escher Map. If BIGG ID's were not used or if the node corresponding to a BIGG ID is absent from the Escher map, data will appear on the left hand side of the Escher Map.
Before Upload:
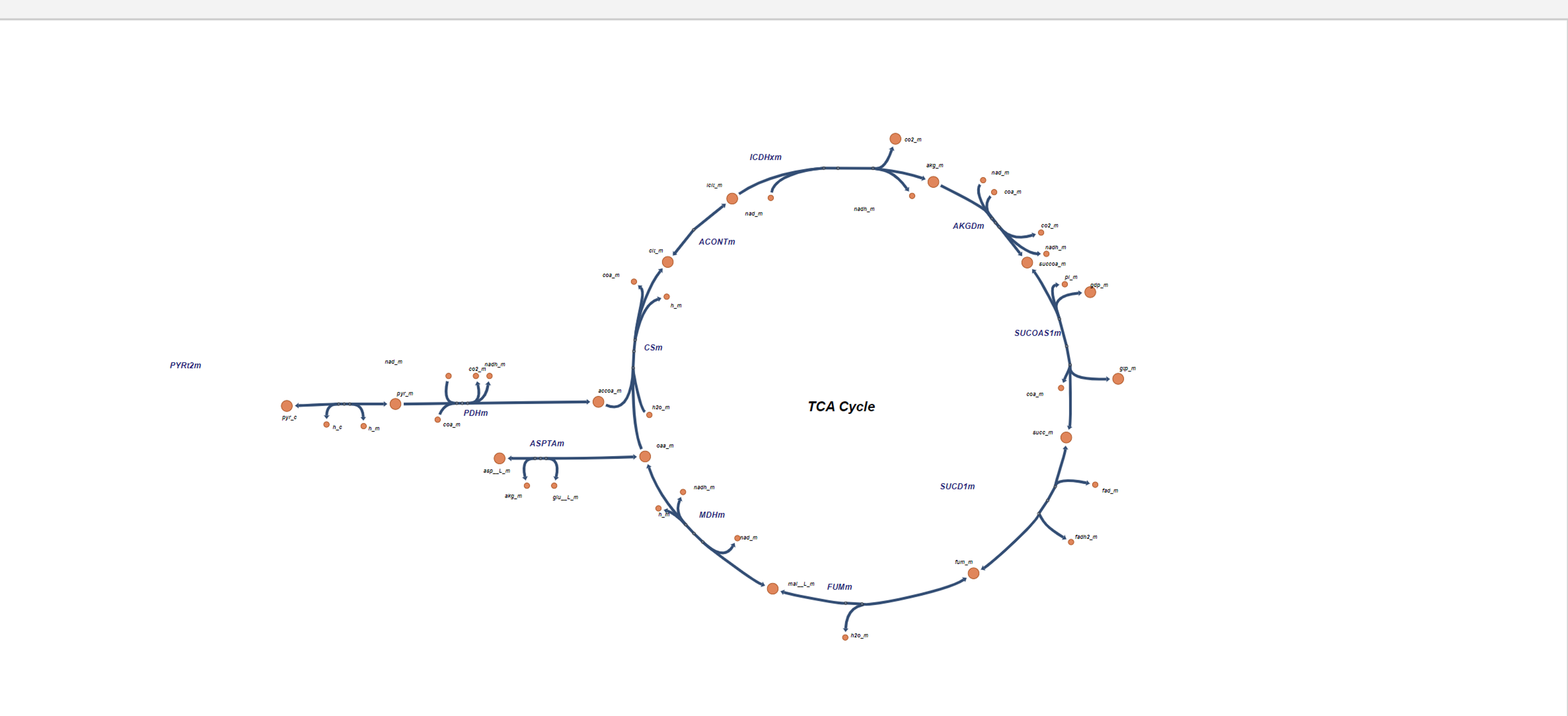
After Upload:

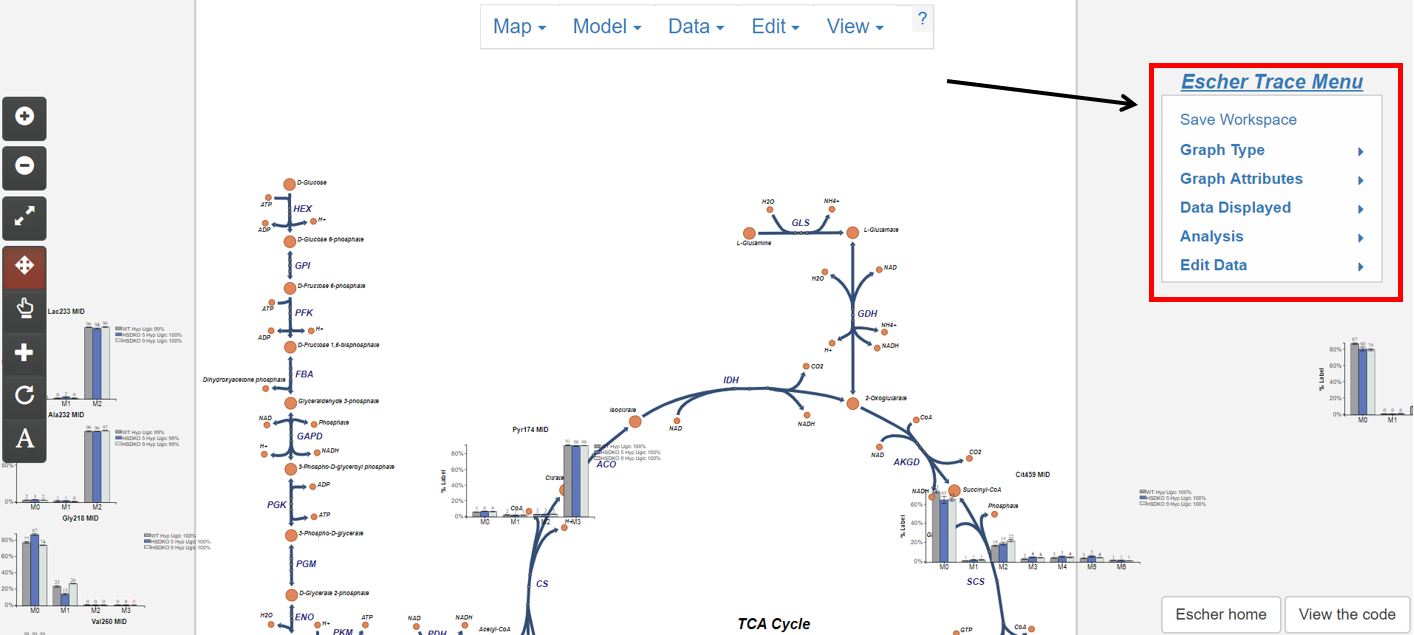
1.4 The Escher-Trace Menu
Most Escher-Trace functionality can be accessed from the Escher-Trace menu found on the right hand side of the screen. Menu options can be accesed by clicking them. Brief descriptions of each menu option can be found below. For more information click the corresponding bold link.
Escher-Trace Menu:
- Graph Type: Switch all displayed graphs to display a specific data type (labeling, abundance, enrichment)
- Graph Attributes: Change the size and color scheme of all Escher-Trace graphs.
- Data Displayed: Alter which metabolites and metabolite isotopologues are graphed, and introduce carbon diagrams to the Escher-Trace workspace
- Analysis: Generate graphs comparing metabolite data, normalize metabolite abundances, enter time point information to access kinetic graphs, and perform metabolite quantitation.
- Edit Data: Alter data file organization, condition order, and condition names.
- Save Workspace: Save the Escher-Trace workspace to be reuploaded later.